環境
TensorFlowとKerasを使ったDeep Learningを習得する必要があったので調べました。
今回はWindowsノートパソコンで行ったのでCPUで計算するtensorflow-cpuを使いました。
データセット作成、学習、評価、テストまで行っています。
プログラムはLinux、Windowsの両方で動くようにしています。
また、google-images-downloadが使えないので、学習用データと検証用データのgrape、orange、strawberryの画像は自分で準備する必要があります。
修正
2024.04.03 現状に合わせて修正。
2022.11.23 ソースを修正。
データの種類など
基本的な事項が分かっていないので以下を参考にしました。



環境
WindowsとLinux(WSL2)の両方で動作確認しました。
Lenovo IdeaPad5 15ITL05
- i5-1135G7 2.4GHz
- Memory 8 Gbyte
Windows11
Windows11
- WSL2
- Debian bookworm
Python 3.10.11
TensorFlow
- tensorflow-cpu==2.16.1
icrawler 0.6.7
WindowsでTensorFlow 2.11以降を使う場合は、公式ページによるとtensorflow-cpu、またはWSL2を使う必要があるようです。
今回は、貧弱なノートパソコンで行うのでtensorflow-cpuを使います。

ディレクトリ構成
dataset.py train.py predict.py model.py data - grape - orange - strawberry data-validation - grape - orange - strawberry predict - 5a.jpg(検証する画像)
Pythonのインストール
Windowsは、Microsft Storeで3.10系をインストール、またはインストーラをダウンロードします。
Linuxはpipenvなどで3.10系の仮想環境を作ります。
3.11系以上は試していません。
モジュールのインストール
コマンドプロンプトを管理者権限で起動してインストールします。
足りないものがあれば、その都度インストールします。
pipenvを使っている場合は、pipをpipenvに置き換えてください。
python.exe -m pip install --upgrade pip pip install tensorflow-cpu pip install keras pip install gast pip install numpy pip install Pillow pip install tensorboard
必要ならJupyterLabもインストールします。
pip install jupyterlab
JupyterLabの起動は、コマンドプロンプトで以下のようにコマンドを打ちます。
jupyter lab
画像の収集
icrawlerを使います。
pip install icrawler pip install lxml pip install bs4

画像の収集に使うプログラム(image-crawler.py)です。
重複や指定した条件と異なる画像が含まれる可能性が高いので、収集後に手作業で分別する必要があります。
from icrawler.builtin import BingImageCrawler
keywords = ['grape', 'orange', 'strawberry']
# 学習データ
filters = dict(
type = 'photo',
license = 'noncommercial,modify',
)
for keyword in keywords:
crawler = BingImageCrawler(storage = {'root_dir' : './data/' + keyword})
crawler.crawl(
keyword = keyword,
filters = filters,
#min_size = (150, 150),
#max_size = (200, 200),
max_num = 10,
)
# 検証データ
filters = dict(
type = 'photo',
license = 'commercial,modify',
)
for keyword in keywords:
crawler = BingImageCrawler(storage = {'root_dir' : './data-validation/' + keyword})
crawler.crawl(
keyword = keyword,
filters = filters,
#min_size = (60, 60),
#max_size = (140, 140),
max_num = 5,
)
# 評価データ
filters = dict(
type = 'photo',
license = 'noncommercial',
)
for keyword in keywords:
crawler = BingImageCrawler(storage = {'root_dir' : './data-predict/'})
crawler.crawl(
keyword = keyword,
filters = filters,
#min_size = (10, 10),
#max_size = (130, 130),
max_num = 5,
)
作業ディレクトリに移動して実行します。
python image-crawler.py
学習・評価データの作成
学習・検証データを準備します。
python dataset.py
ソースです。
'''
学習・検証データ作成
'''
from PIL import Image
from pathlib import Path
import numpy as np
'''
クラスラベル
0: grape
1: orange
2: strawberry
'''
classlabels = ['grape', 'orange', 'strawberry']
#classlabels = ['normal', 'abnormal']
# 作業ディレクトリ
path = Path.cwd()
# 学習データ保存ディレクトリ
train_dir = path.joinpath('data')
# 検証データ保存ディレクトリ
vaild_dir = path.joinpath('data-validation')
# 画像の拡張子
img_extension = '*.jpg'
'''
学習データを回転して水増しする。
-40度から40度まで、5度刻みで回転したデータを追加する。
データを増やすとtrain.pyの実行時間が増加する。
'''
rotate_start = -40
rotate_stop = 40
rotate_step = 5
'''
リサイズ設定(単位:pixel)
大きくするとtrain.pyの処理時間が増加する。
'''
resize_settings = (50, 50)
# 前処理済みデータ
train_img = train_dir.joinpath('train_img.npy')
train_label = train_dir.joinpath('train_label.npy')
# 検証データ
valid_img = vaild_dir.joinpath('valid_img.npy')
valid_label = vaild_dir.joinpath('valid_label.npy')
# データ(学習)
img_train = []
label_train = []
# データ(検証)
img_valid = []
label_valid = []
print('Start process \n')
# Label (0:grape 1:apple 2:orange)
for class_num, label in enumerate(classlabels):
print('start: ' + label + '\n')
# 学習データのディレクトリ
photos_dir = train_dir.joinpath(label)
# 画像データを取得
files = photos_dir.glob(img_extension)
#画像を順番に取得
for i, file in enumerate(files):
image = Image.open(file)
# 画像をRGBの3色に変換
image = image.convert('RGB')
# 画像のサイズを揃える
image = image.resize(resize_settings)
# 画像を数字の配列に変換
data = np.asarray(image)
for angle in range(rotate_start, rotate_stop, rotate_step):
# 回転
img_r = image.rotate(angle)
# 画像を数字の配列に変換
data = np.asarray(img_r)
# 追加
img_train.append(data)
label_train.append(class_num)
# 画像の左右反転
img_trans = image.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trans)
img_train.append(data)
label_train.append(class_num)
# 検証データのディレクトリ
photos_dir = vaild_dir.joinpath(label)
# 画像データを取得
files = photos_dir.glob(img_extension)
#画像を順番に取得
for i, file in enumerate(files):
image = Image.open(file)
# 画像をRGBの3色に変換
image = image.convert('RGB')
# 画像のサイズを揃える
image = image.resize(resize_settings)
# 画像を数字の配列に変換
data = np.asarray(image)
img_valid.append(data)
label_valid.append(class_num)
# リストをTensorflowが扱いやすいようにnumpyの配列に変換
img_train = np.array(img_train)
label_train = np.array(label_train)
img_valid = np.array(img_valid)
label_valid = np.array(label_valid)
print('------------- img_train -------------')
print(' タイプ:', type(img_train.ndim))
print('各次元のサイズ:', img_train.shape)
print(' 全要素数:', img_train.size)
print('\n')
print('------------- label_train -------------')
print(' タイプ:', type(label_train.ndim))
print('各次元のサイズ:', label_train.shape)
print(' 全要素数:', label_train.size)
print('\n')
print('------------- img_valid -------------')
print(' タイプ:', type(img_valid.ndim))
print('各次元のサイズ:', img_valid.shape)
print(' 全要素数:', img_valid.size)
print('\n')
print('------------- label_valid -------------')
print(' タイプ:', type(label_valid.ndim))
print('各次元のサイズ:', label_valid.shape)
print(' 全要素数:', label_valid.size)
print('\n')
# 学習データ・ラベルを保存
np.save(train_img, img_train)
np.save(train_label, label_train)
# 検証データ・ラベルを保存
np.save(valid_img, img_valid)
np.save(valid_label, label_valid)
print('End process \n')
モデルの学習・評価
モデルを学習させて評価します。
Tensorboardのログ出力、過学習の対策、モデル自動保存を組み込みます。
また、スクリプトの実行部「train.py」からアーキテクチャ部「model.py」を分離しています。
python train.py
ソース:train.py
ソース「train.py」です。
'''
学習・検証プログラム
'''
from tensorflow import keras
from keras.models import Sequential
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
from keras.utils import to_categorical
import numpy as np
from pathlib import Path
from model import CNNModel
'''
クラスラベル
0: grape
1: orange
2: strawberry
'''
classlabels = ['grape', 'orange', 'strawberry']
#classlabels = ['normal', 'abnormal']
# 作業ディレクトリ
path = Path.cwd()
# 学習データ保存ディレクトリ
train_dir = path.joinpath('data')
# 前処理済みデータ
log_tensorboard = train_dir.joinpath('log_tensorboard')
'''
前処理済みデータ
dataset.pyを実行して作成する。
'''
train_img = train_dir.joinpath('train_img.npy')
train_label = train_dir.joinpath('train_label.npy')
'''
学習済みモデルのファイル名
拡張子は「.keras」にする必要がある。
'''
model_file = train_dir.joinpath('cnn_h5.keras')
'''
Denseレイヤー
model.pyで使う。
softmax
多クラスの分類(0.0~1.0の出力で、出力の総和が1.0)
sigmoid
2値の分類(0 or 1:0.0~1.0の出力)
Dense関数の第1引数はクラス数と揃える。
![]()
![]() www.tensorflow.org
'''
class_number = len(classlabels)
if len(classlabels) == 2:
activation_method = 'sigmoid'
else:
activation_method ='softmax'
'''
fitのパラメータ
学習回数
データセット / batch_size
valid_split = 0.1
データの最後の10%を検証に使う。
shuffle
default is True
検証用データはシャッフルされない。
'''
epoch_size = 200
batch_size = 10
valid_split = 0.1
# 検証データ保存ディレクトリ
valid_dir = path.joinpath('data-validation')
# 検証データ
# dataset.pyで作成する。
valid_img = valid_dir.joinpath('valid_img.npy')
valid_label = valid_dir.joinpath('valid_label.npy')
def main():
# 保存した学習データ・ラベル(numpyデータ)を読み込む
img_train = np.load(train_img, allow_pickle=True)
label_train = np.load(train_label, allow_pickle=True)
# 保存した検証データ・ラベル(numpyデータ)を読み込む
img_valid = np.load(valid_img, allow_pickle=True)
label_valid = np.load(valid_label, allow_pickle=True)
# 0~255の整数範囲になっているため、0~1間に数値が収まるよう正規化
img_train = img_train.astype('float') / img_train.max()
img_valid = img_valid.astype('float') / img_valid.max()
# クラスラベルの正解値は1、他は0になるようにラベル配列に変更
# 0 -> [1, 0]
# 1 -> [0, 1]
label_train = to_categorical(label_train, len(classlabels))
label_valid = to_categorical(label_valid, len(classlabels))
# モデル学習とアーキテクチャの表示
model = model_train(img_train, label_train)
print(model.summary())
# モデル検証
evaluate(model, img_valid, label_valid)
#モデル学習関数
def model_train(img_train, label_train):
# インスタンス
model = Sequential()
'''
畳み込み演算
'''
model = CNNModel(model, img_train, class_number, activation_method)
'''
EarlyStopping: 過学習を避ける。(patience:指定回数で改善なしの場合に停止)
ModelCheckpoint: epoch終了時にモデルを保存する。(中断した場合、その時点から学習を再開可能)
Tensorboard: 可視化(tensorboard --logdir log_tensorboard)
'''
callbacks = [
EarlyStopping(patience=10, restore_best_weights=True),
ModelCheckpoint(filepath=model_file, save_best_only=True),
#TensorBoard(log_dir=log_tensorboard, histogram_freq=1)
TensorBoard(log_dir=log_tensorboard)
]
'''
モデル学習
ログ出力なし:verbose=0
'''
model.fit(
img_train,
label_train,
epochs = epoch_size,
batch_size = batch_size,
validation_split = valid_split,
callbacks = callbacks,
#verbose = 0,
)
# モデルの結果を保存
#model.save(model_file)
return model
# モデル検証
def evaluate(model, x, y):
scores = model.evaluate(x, y, verbose=1)
print('\n-------------------------------')
print('Verification Loss: ', scores[0])
print('Verification Accuracy: ', scores[1])
print('-------------------------------')
# コマンド実行用
if __name__ == '__main__':
model = main()
www.tensorflow.org
'''
class_number = len(classlabels)
if len(classlabels) == 2:
activation_method = 'sigmoid'
else:
activation_method ='softmax'
'''
fitのパラメータ
学習回数
データセット / batch_size
valid_split = 0.1
データの最後の10%を検証に使う。
shuffle
default is True
検証用データはシャッフルされない。
'''
epoch_size = 200
batch_size = 10
valid_split = 0.1
# 検証データ保存ディレクトリ
valid_dir = path.joinpath('data-validation')
# 検証データ
# dataset.pyで作成する。
valid_img = valid_dir.joinpath('valid_img.npy')
valid_label = valid_dir.joinpath('valid_label.npy')
def main():
# 保存した学習データ・ラベル(numpyデータ)を読み込む
img_train = np.load(train_img, allow_pickle=True)
label_train = np.load(train_label, allow_pickle=True)
# 保存した検証データ・ラベル(numpyデータ)を読み込む
img_valid = np.load(valid_img, allow_pickle=True)
label_valid = np.load(valid_label, allow_pickle=True)
# 0~255の整数範囲になっているため、0~1間に数値が収まるよう正規化
img_train = img_train.astype('float') / img_train.max()
img_valid = img_valid.astype('float') / img_valid.max()
# クラスラベルの正解値は1、他は0になるようにラベル配列に変更
# 0 -> [1, 0]
# 1 -> [0, 1]
label_train = to_categorical(label_train, len(classlabels))
label_valid = to_categorical(label_valid, len(classlabels))
# モデル学習とアーキテクチャの表示
model = model_train(img_train, label_train)
print(model.summary())
# モデル検証
evaluate(model, img_valid, label_valid)
#モデル学習関数
def model_train(img_train, label_train):
# インスタンス
model = Sequential()
'''
畳み込み演算
'''
model = CNNModel(model, img_train, class_number, activation_method)
'''
EarlyStopping: 過学習を避ける。(patience:指定回数で改善なしの場合に停止)
ModelCheckpoint: epoch終了時にモデルを保存する。(中断した場合、その時点から学習を再開可能)
Tensorboard: 可視化(tensorboard --logdir log_tensorboard)
'''
callbacks = [
EarlyStopping(patience=10, restore_best_weights=True),
ModelCheckpoint(filepath=model_file, save_best_only=True),
#TensorBoard(log_dir=log_tensorboard, histogram_freq=1)
TensorBoard(log_dir=log_tensorboard)
]
'''
モデル学習
ログ出力なし:verbose=0
'''
model.fit(
img_train,
label_train,
epochs = epoch_size,
batch_size = batch_size,
validation_split = valid_split,
callbacks = callbacks,
#verbose = 0,
)
# モデルの結果を保存
#model.save(model_file)
return model
# モデル検証
def evaluate(model, x, y):
scores = model.evaluate(x, y, verbose=1)
print('\n-------------------------------')
print('Verification Loss: ', scores[0])
print('Verification Accuracy: ', scores[1])
print('-------------------------------')
# コマンド実行用
if __name__ == '__main__':
model = main()

ソース:model.py
CNNのアーキテクチャ部のソース「model.py」です。
'''
CNN architecture
train.pyで利用する。
'''
from keras.layers import Activation, Dropout, Flatten, Dense, Conv2D, MaxPooling2D
from keras.optimizers import Adam, Adagrad, RMSprop
'''
第1引数:モデルインスタンス
第2引数:学習データ(numpyデータ)
第3引数:クラスの数(分類カテゴリーの数)
第4引数:活性化関数の種類
'''
def CNNModel(model, inputshape, class_number, activation_method):
#filters_num = 32
#kernel_size = (3, 3)
'''
1層目 (畳み込み)
3x3のKernel
32種類のFilter
'''
#model.add(Conv2D(filters_num, kernel_size, padding='same', input_shape=inputshape.shape[1:]))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=inputshape.shape[1:]))
# 2層目(Max Pooling)
model.add(Conv2D(32, (3, 3), activation='relu'))
# 3層目 (Max Pooling)
model.add(MaxPooling2D(pool_size=(2, 2)))
# Dropout <= 0.5
model.add(Dropout(0.3))
# 4層目 (畳み込み)
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
# 5層目 (畳み込み)
model.add(Conv2D(64, (3, 3), activation='relu'))
# 6層目 (Max Pooling)
model.add(MaxPooling2D(pool_size=(2, 2)))
# データを1次元化
model.add(Flatten())
# 7層目 (全結合層)
model.add(Dense(512, activation='relu'))
# Dropout <= 0.5
model.add(Dropout(0.5))
'''
出力層
'''
model.add(Dense(class_number, activation=activation_method))
'''
最適化アルゴリズム
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers
'''
#opt = Adam()
opt = Adam(learning_rate=0.001)
#opt = Adam(learning_rate=0.005, beta_1=0.9)
#opt = Adagrad(learning_rate=0.005)
#opt = RMSprop(learning_rate=0.005, momentum=0.9)
#opt = RMSprop(learning_rate=0.005, decay=1e-6)
#opt = RMSprop()
# 損失関数
model.compile(
loss = 'categorical_crossentropy',
optimizer = opt,
metrics = ['accuracy']
)
return model
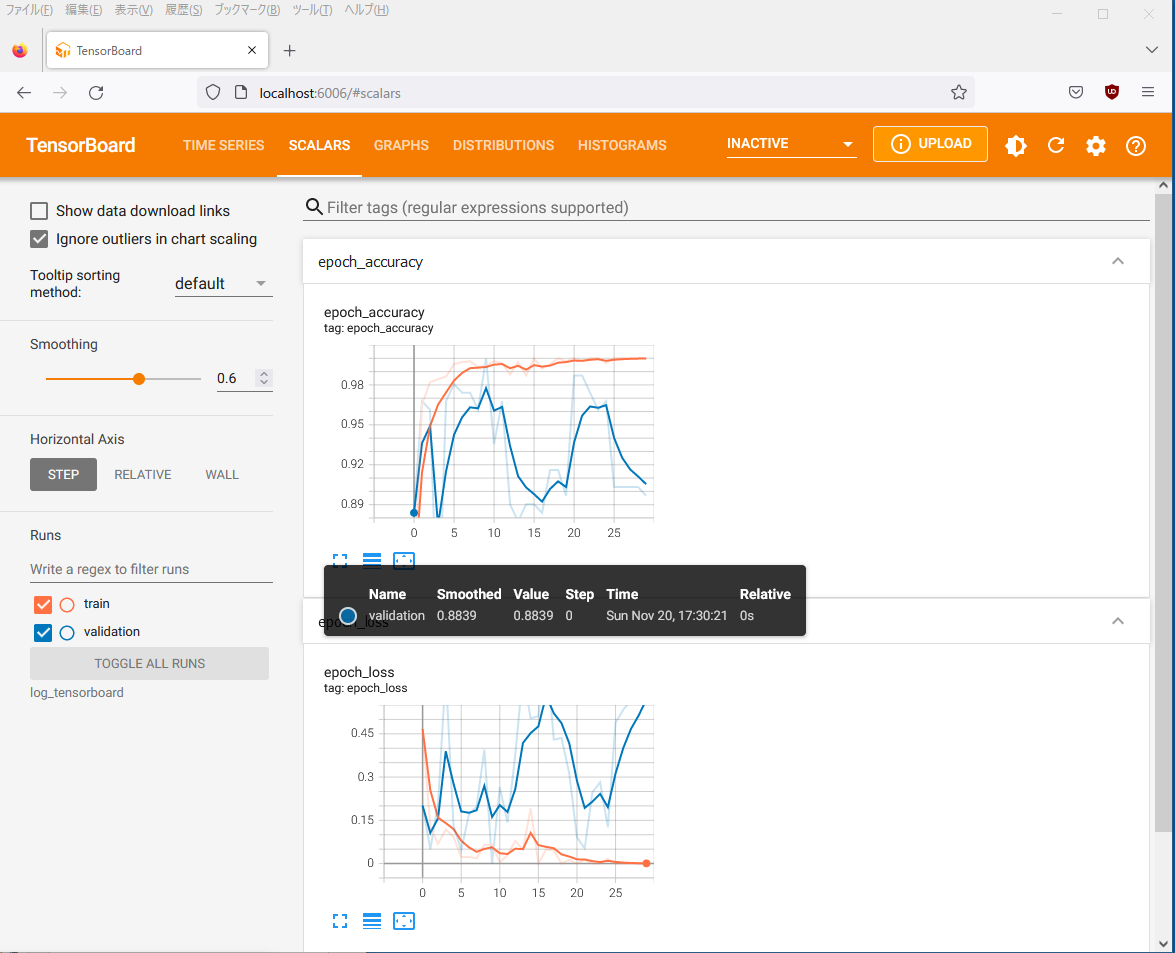
TensorBoardによる学習状況の可視化
学習状況を可視化するためにTensorBoardを実行して、Webブラウザでアクセスします。
cd data tensorboard --logdir log_tensorboard Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.11.0 at http://localhost:6006/ (Press CTRL+C to quit)

推論(1枚の画像)
Googleの仕様が変更になったせいか、google-images-downloadが使えないので、自力で集めます。
イチゴ、オレンジ、ブドウのいずれかの画像を1枚だけJPEG形式で収集します。
predictディレクトリに画像が保存されるように指定します。
画像ファイル名は、ダウンロード時の状態で構いません。
スクリプトでは1枚の画像を推論します。
googleimagesdownload --limit 1 --output_directory predict --type photo --format jpg --language "English" --keywords "grape" googleimagesdownload --limit 1 --output_directory predict --type photo --format jpg --language "English" --keywords "orange" googleimagesdownload --limit 1 --output_directory predict --type photo --format jpg --language "English" --keywords "strawberry"
ソースです。
'''
指定した画像ファイルの推論を行う。
'''
import tensorflow
from tensorflow import keras
from PIL import Image
from pathlib import Path
import numpy as np
'''
クラスラベル
0: grape
1: orange
2: strawberry
'''
classlabels = ['grape', 'orange', 'strawberry']
#classlabels = ['normal', 'abnormal']
# 作業ディレクトリ
path = Path.cwd()
# 学習データ保存ディレクトリ
train_dir = path.joinpath('data')
# 検証用の画像ファイル
predict_file = Path(str(path), 'data-predict', '5a.jpg')
'''
リサイズ設定(単位:pixel)
大きくすると処理時間が増加する。
'''
resize_settings = (50, 50)
'''
train.pyで作成した学習済みモデルのファイル名
拡張子は「.keras」にする必要がある。
'''
model_file = train_dir.joinpath('cnn_h5.keras')
# 実行関数
def main():
# 推論データ格納
X_predict = []
# 画像読み込み
image = Image.open(predict_file)
# RGB変換
image = image.convert("RGB")
# リサイズ
image = image.resize(resize_settings)
# 数値の配列変換
data = np.asarray(image)
X_predict.append(data)
X_predict = np.array(X_predict)
# 学習済みモデルを読み込む
model = keras.models.load_model(model_file)
# numpy形式のデータX_predictを与えて予測値を得る
model_output = model.predict([X_predict])[0]
# 推定値 argmax()を指定しmodel_outputの配列にある推定値が一番高いインデックスを渡す
predicted = model_output.argmax()
# アウトプット正答率
accuracy = int(100 * model_output[predicted])
print("{0} ({1} %)".format(classlabels[predicted], accuracy))
# 推論した画像を表示する
image.show()
# コマンド実行用
if __name__ == '__main__':
model = main()
推論(指定したディレクトリに保存された複数の画像)
指定したディレクトリに保存された複数の画像を順番に推論します。
また、推論の確率が低かったり、誤った判定をした場合にGmailを経由してメールを送信します。
メール送信が不要な場合は、該当箇所をコメントしてください。
'''
指定したディレクトリに保存された複数の画像に対して推論を行い、
異常と判定された場合、結果をメールで送信する。
'''
from tensorflow import keras
from PIL import Image
from pathlib import Path
import numpy as np
# 自作のGmail送信関数を読み込む
from gmail import gmail_send_proc
'''
クラスラベル
0: grape
1: orange
2: strawberry
'''
classlabels = ['grape', 'orange', 'strawberry']
#classlabels = ['normal', 'abnormal']
# 作業ディレクトリ
path = Path.cwd()
# 検証する画像の拡張子
img_extension = '*.jpg'
# 検証用の画像を保存したディレクトリ
predict_dir = Path(str(path), 'data-predict')
# 学習データ保存ディレクトリ
train_dir = path.joinpath('data')
'''
リサイズ設定(単位:pixel)
大きくすると処理時間が増加する。
'''
resize_settings = (50, 50)
'''
train.pyで作成した学習済みモデルのファイル名
拡張子は「.keras」にする必要がある。
'''
model_file = train_dir.joinpath('cnn_h5.keras')
# 実行関数
def main():
# 学習済みモデルを読み込む
model = keras.models.load_model(model_file)
# 画像データ一覧を取得
files = predict_dir.glob(img_extension)
#画像を順番に取得
for i, file in enumerate(files):
# 推論データ格納
X_predict = []
# 画像読み込み
image = Image.open(file)
# RGB変換
image = image.convert("RGB")
# リサイズ
image = image.resize(resize_settings)
# 数値の配列変換
data = np.asarray(image)
X_predict.append(data)
X_predict = np.array(X_predict)
# numpy形式のデータX_predictを与えて予測値を得る
model_output = model.predict([X_predict])[0]
# 推定値 argmax()を指定しmodel_outputの配列にある推定値が一番高いインデックスを渡す
predicted = model_output.argmax()
# アウトプット正答率
accuracy = int(100 * model_output[predicted])
print("{0} ({1} %)".format(classlabels[predicted], accuracy))
# 推論した画像を表示する
image.show()
# 正答率が95%以上の場合はプログラム終了。
#if accuracy == 100:
#if accuracy >= 95:
# continue
# 判定が正常の場合はプログラム終了。
#if classlabels[predicted] == 'normal':
#if classlabels[predicted] == classlabels[0]:
# continue
# 異常の場合は、Gmailを送信する。
'''
_subject: メールのタイトル
_from: Google OAuth2の証明書を作成したGoogleアカウント
_to: メールの宛先
_msg: メール本文
'''
_subject = '[Project] 異常発生'
_from = 'hoge1@abc.com'
_to = 'hoge2@abc.com'
_msg = '検証結果' + '\n'
_msg += 'ファイル名' + '\n' + str(file) + '\n\n'
_msg += '検証結果' + '\n' + str(classlabels[predicted]) + '\n' + str(accuracy) + '%' + '\n'
gmail_send_proc(_subject, _from, _to, _msg)
# コマンド実行用
if __name__ == '__main__':
model = main()
Gmailを送信する関数
Gmailを送信する関数を記述したファイルの内容です。
GoogleのOAuth2.0の証明書ファイル「credentials.json」は、プログラムと同じディレクトリに置きます。
Gmailを扱うためのライブラリをインストールします。
pip install google-auth-httplib2 pip install google-auth-oauthlib pip install googleapis-common-protos pip install google-api-python-client
ソースです。
'''
coding: utf-8
Gmailを使ってメールを送信するライブラリ。
GoogleでOAuth2の発行手続きを行い、証明書をダウンロードして使う。
'''
from pathlib import Path
from email.mime.text import MIMEText
from apiclient import errors
import base64
import os
# Google OAuth2
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
# 作業ディレクトリ
path = Path.cwd()
# OAuth2 for google
# https://developers.google.com/gmail/api/auth/scopes
API_SERVICE_NAME = 'gmail'
API_VERSION = 'v1'
SCOPES = ['https://www.googleapis.com/auth/gmail.send']
CLIENT_SECRETS_FILE = path.joinpath('credentials.json')
TOKEN_PICKLE_FILE = path.joinpath('token.pickle')
'''
_subject: メールのタイトル
_from: Google OAuth2の証明書を作成したGoogleアカウント
_to: メールの宛先
_msg: メール本文
'''
def gmail_send_proc(_subject, _from, _to, _msg):
user_id = 'me'
creds = get_credentials()
service = build("gmail", "v1", credentials=creds, cache_discovery=False)
#creds = get_credentials()
service = build(API_SERVICE_NAME, API_VERSION, credentials=creds, cache_discovery=False)
try:
result = service.users().messages().send(
userId = _from,
body = create_message(_subject, _from, _to, _msg)
).execute()
except errors.HttpError as error:
pass
#print('An error occurred: %s' % error)
'''
Create E-mail Message
'''
def create_message(_subject, _from, _to, _msg):
message = MIMEText(_msg)
message['subject'] = _subject
message['from'] = _from
message['to'] = _to
encode_message = base64.urlsafe_b64encode(message.as_bytes())
return {'raw': encode_message.decode()}
'''
OAuth2(Authentication credential)
![]()
![]() developers.google.com
'''
def get_credentials():
creds = None
if os.path.exists(TOKEN_PICKLE_FILE):
creds = Credentials.from_authorized_user_file(TOKEN_PICKLE_FILE, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
creds = flow.run_local_server(port=0)
#creds = flow.run_console()
with open(TOKEN_PICKLE_FILE, 'w') as token:
token.write(creds.to_json())
return creds
developers.google.com
'''
def get_credentials():
creds = None
if os.path.exists(TOKEN_PICKLE_FILE):
creds = Credentials.from_authorized_user_file(TOKEN_PICKLE_FILE, SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
creds = flow.run_local_server(port=0)
#creds = flow.run_console()
with open(TOKEN_PICKLE_FILE, 'w') as token:
token.write(creds.to_json())
return creds


Comments